HuggingFace发布超200页「实战指南」,从决策到落地「手把手」教你训练大模型
HuggingFace发布超200页「实战指南」,从决策到落地「手把手」教你训练大模型近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。
来自主题: AI技术研报
8262 点击 2025-11-10 09:57
 搜索
搜索
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。

LLM Agent 正以前所未有的速度发展,从网页浏览、软件开发到具身控制,其强大的自主能力令人瞩目。然而,繁荣的背后也带来了研究的「碎片化」和能力的「天花板」:多数 Agent 在可靠规划、长期记忆、海量工具管理和多智能体协调等方面仍显稚嫩,整个领域仿佛一片广袤却缺乏地图的丛林。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可

著名数学家陶哲轩发论文了,除了陶大神,论文作者还包括 Google DeepMind 高级研究工程师 BOGDAN GEORGIEV 等人。论文展示了 AlphaEvolve 如何作为一种工具,自主发现新的数学构造,并推动人们对长期未解数学难题的理解。AlphaEvolve 是谷歌在今年 5 月发布的一项研究,一个由 LLMs 驱动的革命性进化编码智能体。
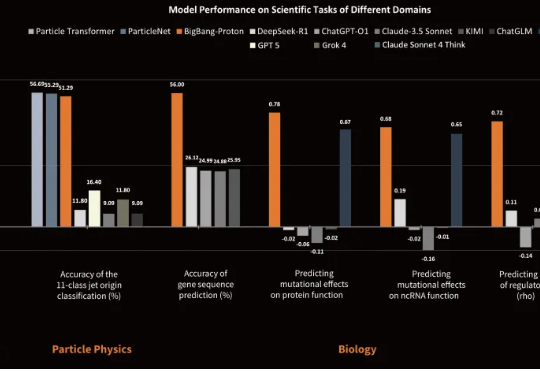
近日,专注于研发物质世界基座模型的公司超越对称(上海)技术有限公司(超对称)发布了新版基座模型 BigBang-Proton,成功实现多个真实世界的专业学科问题与 LLM 的统一预训练和推理,挑战了 Sam Altman 和主流的 AGI 技术路线。
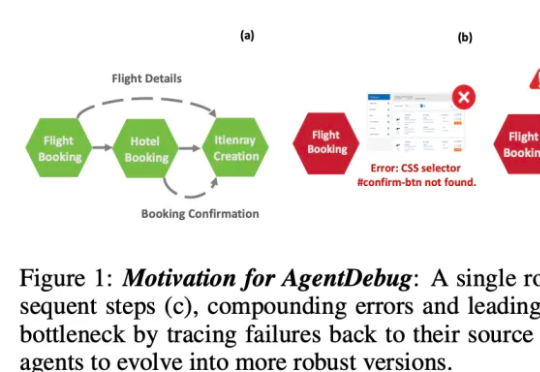
伊利诺伊大学厄巴纳 - 香槟分校(UIUC)等团队近日发布论文,系统性剖析了 LLM 智能体失败的机制,并提出了可自我修复的创新框架 ——AgentDebug。该研究认为,AI 智能体应成为自身的观察者和调试者,不仅仅是被动的任务执行者,为未来大规模智能体的可靠运行和自动进化提供了理论与实践工具。
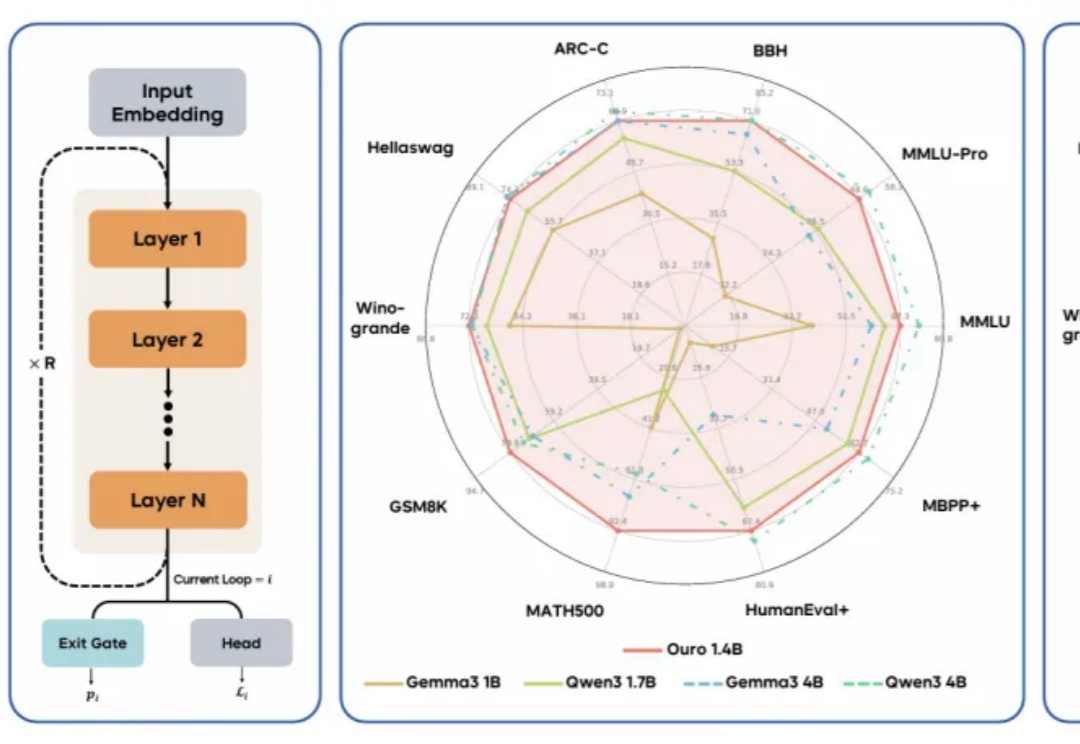
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。

Voice Agent 赛道正在爆发,但它迫切需要一个能让对话真正「流动起来」的底层引擎,一个能撑起下一代交互体验的 TTS 模型。竞争的焦点,已经从 LLM 的「大脑」,延伸到了 TTS 的「嗓音」。谁掌握嗓音,谁就掌握着下一代 AI 商业化的钥匙。而 10 月 30 日 MiniMax 发布的 Speech 2.6 模型,似乎正是一个专为解决这些痛点而来的答案。
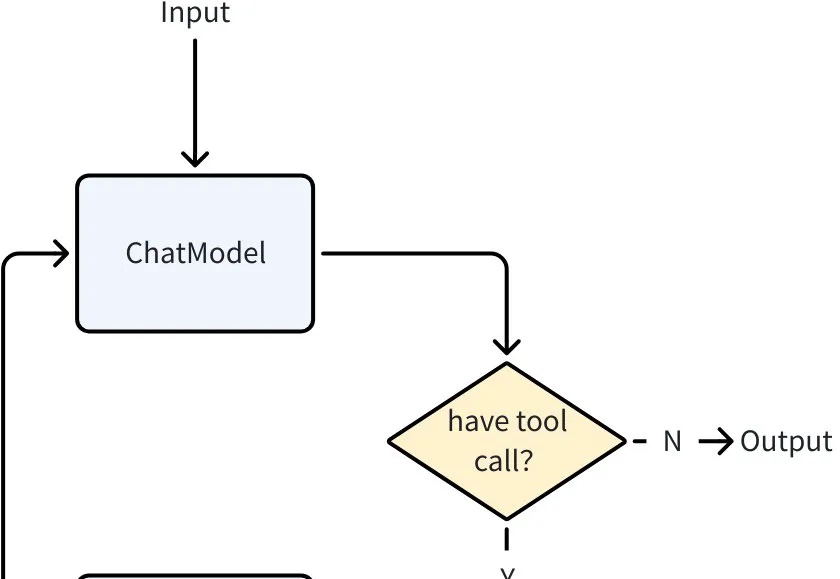
当大语言模型突破了 “理解与生成” 的瓶颈,Agent 迅速成为 AI 落地的主流形态。从智能客服到自动化办公,几乎所有场景都需要 Agent 来承接 LLM 能力、执行具体任务。